


Day to day engineering at a growing start-up is often fueled by demands made by the growth of data volume. Things are no different at Solo! When we started two years ago, we could churn a lot of features pretty quickly with a simple architecture, which we had to change as we grew. Today, I wanted to speak a bit about a specific data growth challenge we were facing and how we tackled the issue a few weeks ago.
At Solo, we have external data feeds that help us understand our driver activity. As more drivers onboard, the volume of this data has seen a sharp uptick. Furthermore, it becomes pretty difficult to control the volumes ingested as the frequency and nature of these feeds are primarily controlled by the third party data feed.
We store a significant portion of the driver data in a Postgres database. There are quite a few tasks that read large chunks of this data at regular intervals. And a few tables are constantly updated with new data from the data feeds.
We have two broad categories of data updates.
- A driver is on a new trip
- A driver’s trip data got updated (ex: a customer tipped them a few hours after the trip completed)
One thing we noticed is that we were getting a large number of irrelevant trip updates. They were irrelevant to us in the sense that no data that we cared about was changed, but our webhooks would be called notifying us that a trip has been updated.
Then we wanted to understand the scale of these spurious updates. We had a clue that the number of updates was insanely high. For example, on a given day, we could get a million trip updates over only a quarter of a million new trips. That didn’t look right to us - I mean most customers won’t tip more than once and the platform (Uber, Instacart) doesn’t really change trip times once they’ve logged it. If they did, drivers would definitely notice and it will create credibility issues for the platform.
We wanted to understand the ratio of spurious updates happening for a start. One idea was that if this was really tiny, we can stop listening to the update webhook and pull any updated trip data just once at the end of day. The compromise here is that we would be delaying delivering updated data to Solo workers by up to a day. This was not a great compromise to be sure, but we didn’t think we had a lot of options at this point. Our database was getting hit hard and it was becoming hard to sustain certain other critical functions.
We wanted to compute the spurious trip updates for each day. This would let us see if there would be a wild fluctuation in spurious calls. We decided to use a Redis HyperLogLog data structure to make this task simpler.
HyperLogLog is like a Bloom Filter that counts the frequency of unique items in a memory efficient manner. In our case, we want to count the number of unique trip updates. We could use a Set data structure, adding the trip id from the update webhook as well. This would take a lot more memory especially as we wanted to store the data for a complete day. HyperLogLog allowed us to spend < 24 KB for the entire day for the two counters we needed to keep.
We would count the number of unique trip IDs that were being called on the update webhook (num_gross_updates). Inside the webhook, after we update the Postgres table, we ask Rails whether any of the columns we care about was actually changed. Based on that we increment another counter, which is the number of unique trip IDs that were actually changed (num_real_updates). Dividing num_real_updates by num_gross_updates gives us the effective trip update ratio.
This is the code that implements the ratio, as you can see it is pretty small and self-explanatory, one of the advantages of pivoting to Redis for our growing data needs.
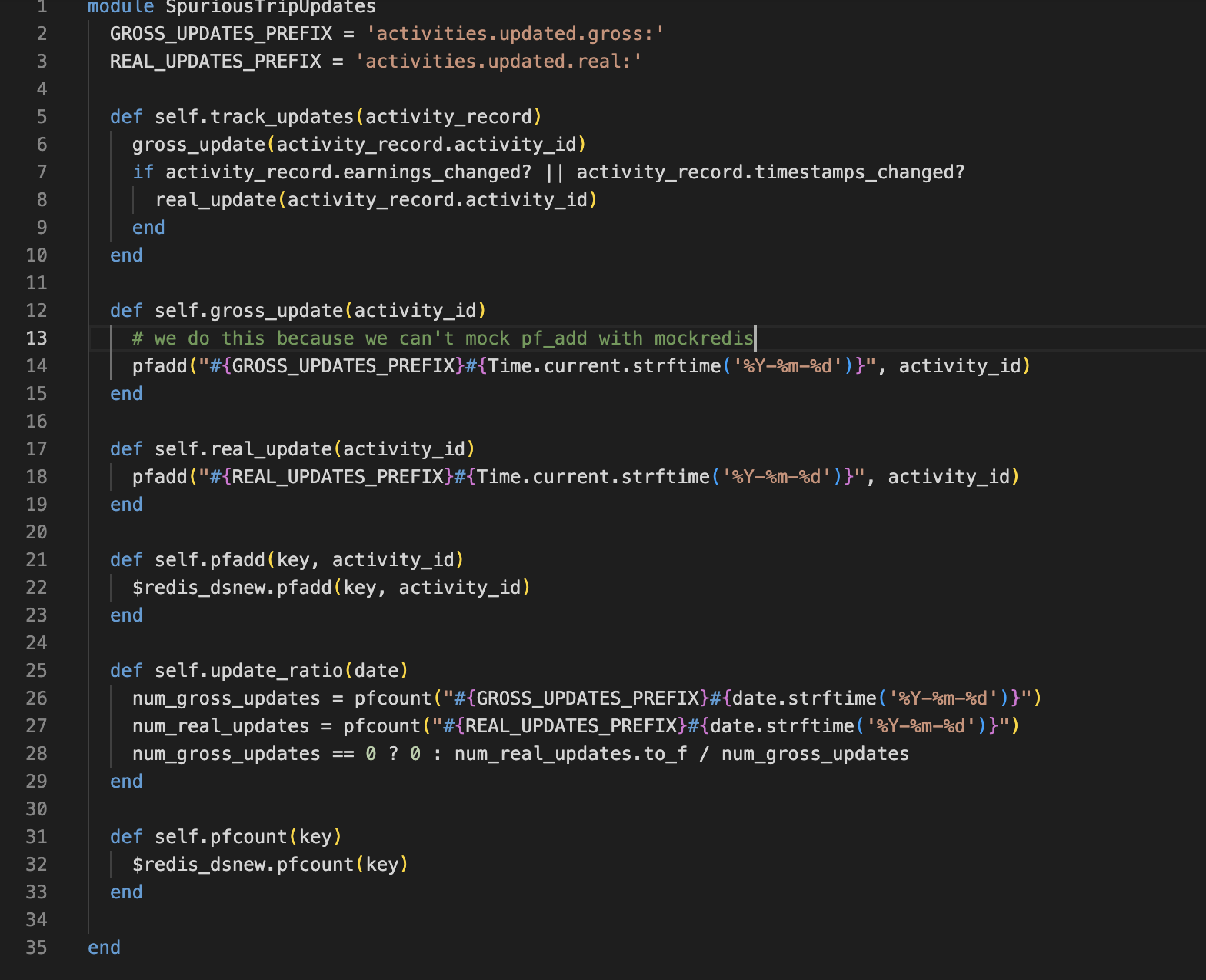
And here is what this ratio looks like over the past week:
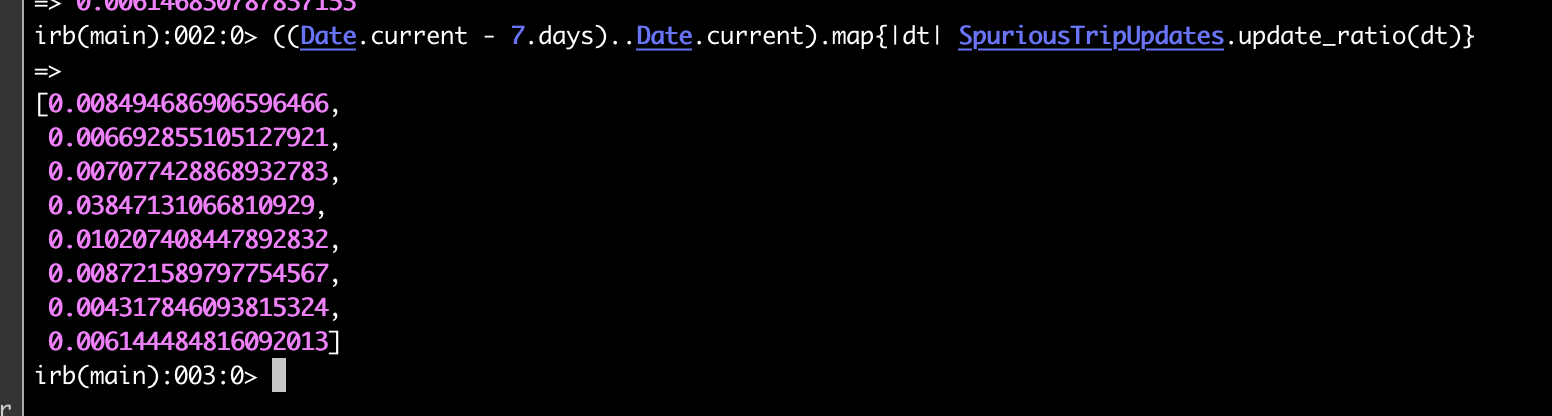
While there is quite a bit of fluctuation, we were correct in our initial hypothesis that very little useful work is being done on the trip update webhook.
Next, we looked in logs to understand the cases where trip updates were useful. Most of the updates tended to be on customer tips. We felt it was important to reflect this on the user’s phone as soon as possible rather than waiting for the end of the day. So how were we to still lessen the load on our database and avoid it churn doing useless work?
Again, we used Redis to build an upfront cache keyed off the activity ID. We used a TTL of 1 day to keep data for all trip updates that happen for a day. Our goal was to use this cache to know if the trip data received from the webhook actually contains any updated data. We could solve that problem by computing a simple hash of all the trip data we cared about and storing it as the cache value. Then we would compute the same hash from within the update hook using the data from the feed and check if the signatures would match for the same trip ID in Redis.
So, if this was the first time we saw the update, we wouldn't have that trip ID in Redis and we would happily update our table, knowing that this was a useful update. Now if we had seen an update for this before (i:e, we found an entry in the Redis cache), and the signatures did not match, we would know that something useful got updated (maybe the tip), and again we would update our Postgres table.
But on the much higher occurrence of a signature match, we would do nothing.
The logs show that a large number of updates are now being avoided:
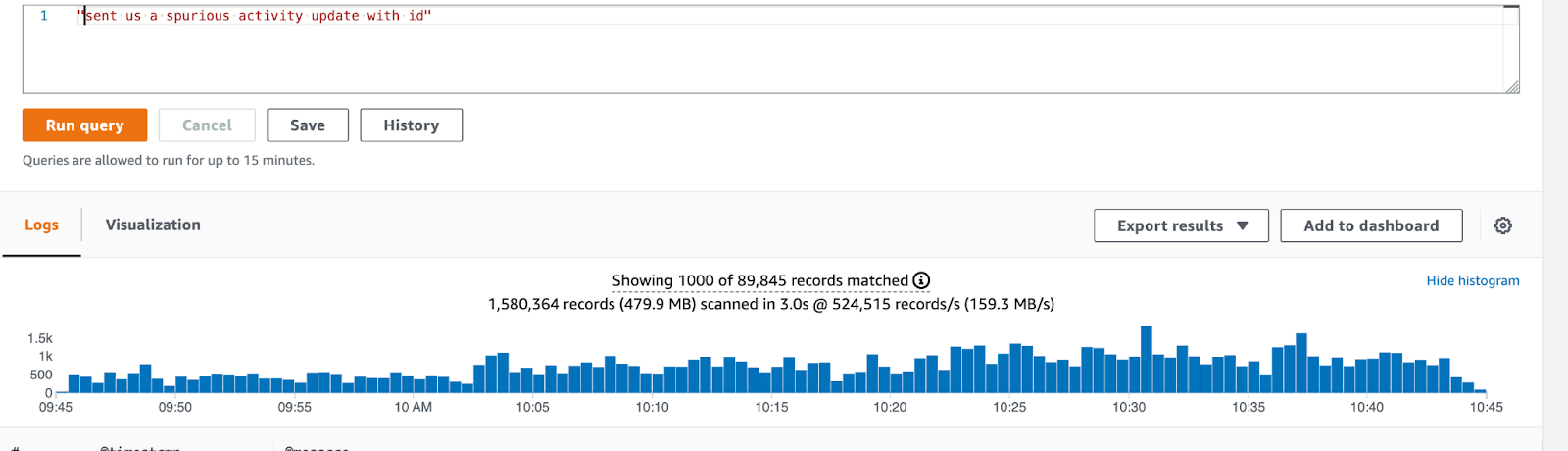
Besides, we now have a powerful lever with which we can control the updates to Postgres. By increasing the Redis cache retention to 2 days, we can clearly reduce the writes further. We should be able to bring down the spurious trip update ratio by increasing the Redis cache retention up to a point.
As a result, we have been able to reduce the load on our database while continuing to provide Solo customers with reliable, fast insights to better run their independent businesses.
Have questions for Thushara? Interested in joining the team? Check out our open engineering jobs or reach out to us at recruiting@worksolo.com.


.png)